JetSpec
Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting
1UC San Diego 2Zhejiang University 3UIUC 4Nanjing University 5StepFun
Speculative decoding hits a scaling ceiling: a larger draft budget helps only while acceptance stays high and drafting stays cheap, and prior heads face a causality-efficiency dilemma: autoregressive drafters condition on the path but cost grows with tree depth, while block-diffusion drafters draft in one pass yet score branches independently, forming individually plausible but mutually inconsistent trees. JetSpec trains a causal parallel draft head over fused hidden states from the frozen target, so a candidate tree’s scores align with the target’s own autoregressive factorization and the full target verifies the whole tree in one forward pass, losslessly. A larger budget then becomes a longer accepted prefix: 9.64× on MATH-500 and 4.58× on open-ended chat (Qwen3-8B, H100, greedy, budget 256), and these carry into real single-stream serving on JetSpec’s own engine.
JetSpec replay
Parallel tree decoding replay
Each panel reaches the same text autoregressive decoding would; JetSpec simply commits more tokens per verified step. The measured speedups across benchmarks are in the results table below.
Tree quality
Tree drafting & verification
Both heads spend the same draft budget; what differs is the quality of the tree that budget buys. JetSpec’s causal head helps in two ways the paper isolates: it keeps the top-ranked branch, the one the verifier follows, faithful to the target, and it does so without tuning the loss weighting.
- accepted path
- drafter’s top pick (not taken)
- rejected
- free bonus
Branch faithfulness
A block-diffusion head produces all positions from one shared hidden state with no causal mask between depths, so the depth-2 distribution never conditions on the token chosen at depth 1. When two positions independently favour tokens that cannot follow each other, the surrogate still scores their composition highly and promotes it to the top of the tree. The causal head masks between depths, anchoring each position to the model’s own choice at the previous one, so its rank-1 branch carries a score the target agrees with.
| Rank-1 branch faithfulness (50 MATH-500 prompts, no loss weighting) | Causal | Diffusion |
|---|---|---|
| Faithful rank-1 (<+5 nats) | 42% | 6% |
| Extreme gap (≥+80 nats) | 0% | 26% |
| Mean accepted length | 9.46 | 4.84 |
No loss-weighting tuning
Bidirectional diffusion heads recover some of this with an exponential loss weighting, but only near a tuned setting: the diffusion head peaks at a single weighting and collapses at the extremes, while the causal head holds 8.3–8.5× across the whole range. The causal mask removes the need to tune any weighting at all.
| MATH-500 speedup by loss-weighting | γ=0 | γ=3 | γ=7 | γ=15 |
|---|---|---|---|---|
| Causal (JetSpec) | 8.29 | 8.50 | 8.40 | 8.41 |
| Diffusion head | 5.46 | 8.16 | 8.36 | 6.17 |
Serving
The engine
JetSpec runs on its own standalone inference engine, with no dependency on an external serving stack. It takes the minimalist philosophy of nano-vLLM as a starting point but is otherwise its own engine. The target verifies every speculative tree node in one forward pass under a tree-attention mask, and the acceptance rule is lossless by construction, preserving the target’s output exactly. The mean accepted length is therefore a property of the model and draft tree rather than the hardware, while the end-to-end speedup and throughput depend on the GPU’s compute and bandwidth. We implement paged FlashAttention kernels in both Triton and NVIDIA CuTe DSL that apply the tree mask directly inside the attention computation, without materializing a dense per-request mask.
JetSpec on its own engine, with no external serving dependency, on a single B200 (Qwen3-8B, budget 127), generating 12 chained MATH-500 problems. Per-problem throughput rises and falls with acceptance: peaking at 1456 tok/s and sustaining ~1000 tok/s on average, at τ=9.29 accepted tokens per round. Real JetSpec e3-engine generation; per-round constant-time pacing reconstructed from the measured throughput.
Approach
How JetSpec works
Head-based speculative decoding faces a causality-efficiency dilemma: an autoregressive draft head conditions each token on its path but pays a forward pass per depth, while a block-diffusion head drafts a whole block in one pass yet scores positions independently, composing branches the target rejects. JetSpec keeps the one-pass efficiency and recovers the conditioning. Over fused hidden states from the frozen target, deep features already shown to encode several future tokens, it trains a causal parallel draft head: a single forward pass emits a scored candidate tree whose branch scores follow the target’s own autoregressive factorization rather than an independent per-position surrogate. The frozen target then verifies the entire tree in one pass and commits the longest path it agrees with, leaving the target’s output distribution exactly unchanged.
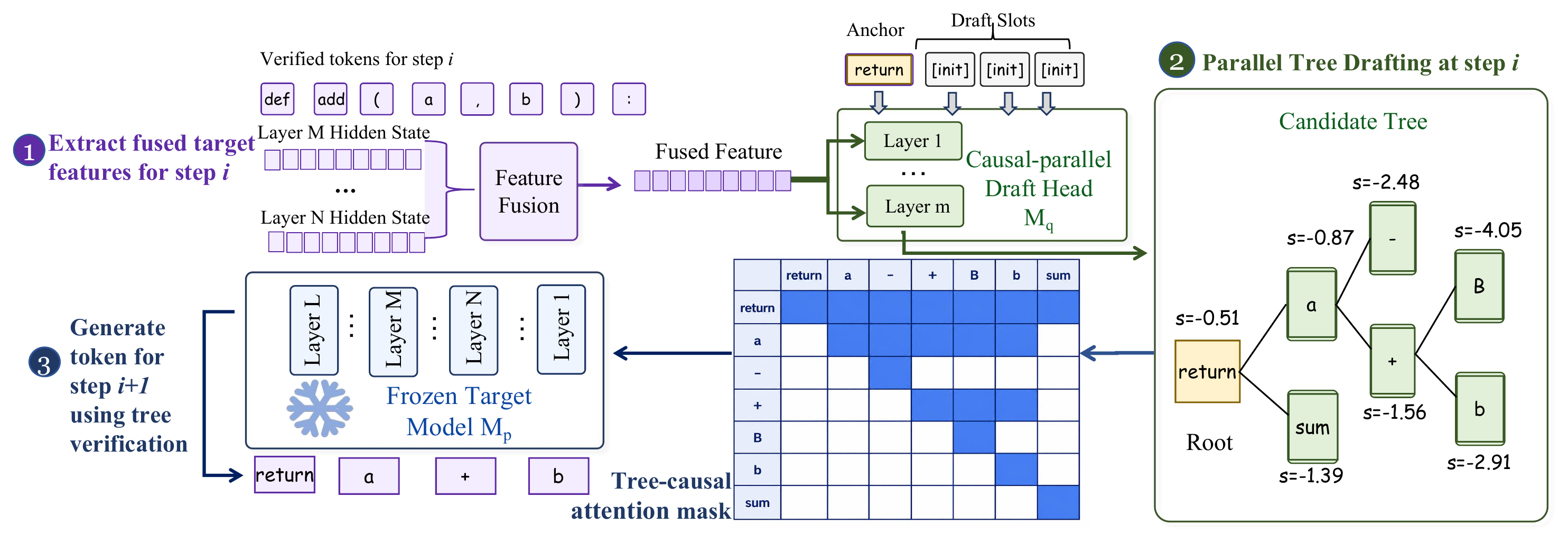
Training the head
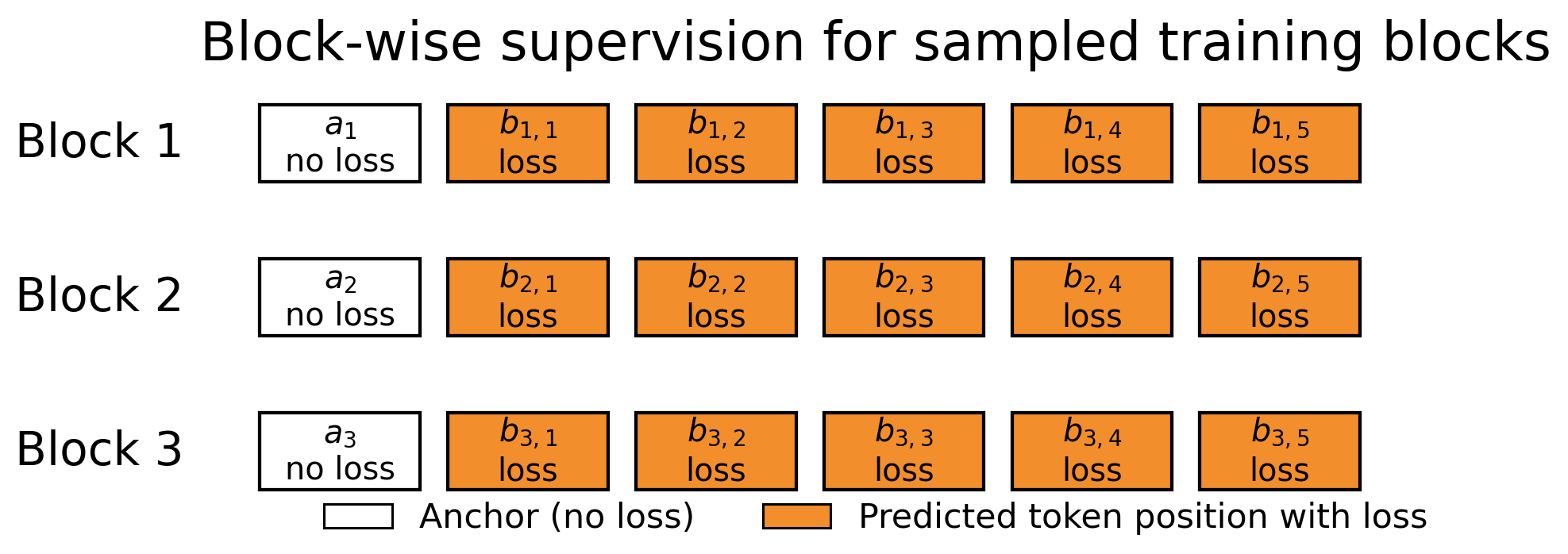
Only the head is trained; the target stays frozen, so JetSpec attaches to a model already in production without touching its weights. The head reads fused multi-layer features from the target and is supervised against the target’s own next-token distributions rather than hard labels, so it inherits the relative preferences among candidate tokens that a tree needs in order to rank branches. We train with a causal mask over selected anchor positions, with each anchor expanded into a 16-token draft block. Each draft position attends to preceding positions within its block, enabling a single parallel pass to produce an internally consistent draft tree.
At budget 256 (greedy), JetSpec leads DDTree on every benchmark: MATH-500 9.64× vs 8.78×, GSM8K 7.82× vs 7.04×, HumanEval 7.12× vs 6.31×. The full grid:
| Method | Budget | GSM8K | MATH-500 | AIME25 | HumanEval | MBPP | LCB | MT-Bench | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Spd | τ | Spd | τ | Spd | τ | Spd | τ | Spd | τ | Spd | τ | Spd | τ | ||
| Temperature = 0 (greedy) | |||||||||||||||
| EAGLE-3 | 64 | 2.53 | 4.31 | 2.36 | 4.13 | 2.35 | 4.04 | 2.49 | 4.26 | 2.22 | 3.81 | 2.09 | 3.62 | 2.19 | 3.88 |
| DDTree | 64 | 5.63 | 6.18 | 6.51 | 7.16 | 6.40 | 6.96 | 5.08 | 5.57 | 4.99 | 5.49 | 5.47 | 6.06 | 3.74 | 4.51 |
| DDTree | 128 | 6.63 | 7.31 | 8.27 | 9.19 | 7.93 | 8.66 | 5.93 | 6.52 | 5.70 | 6.28 | 6.42 | 7.25 | 4.12 | 5.14 |
| DDTree | 256 | 7.04 | 7.77 | 8.78 | 9.81 | 8.33 | 9.24 | 6.31 | 6.96 | 6.09 | 6.70 | 6.75 | 7.72 | 4.26 | 5.41 |
| JetSpec | 64 | 5.98 | 6.56 | 6.76 | 7.42 | 6.47 | 7.00 | 5.53 | 6.06 | 5.34 | 5.88 | 5.95 | 6.59 | 3.97 | 4.77 |
| JetSpec | 128 | 7.34 | 8.05 | 8.93 | 9.95 | 8.26 | 9.10 | 6.66 | 7.28 | 6.31 | 6.95 | 7.29 | 8.21 | 4.37 | 5.52 |
| JetSpec | 256 | 7.82 | 8.62 | 9.64 | 10.76 | 8.78 | 9.82 | 7.12 | 7.78 | 6.73 | 7.43 | 7.67 | 8.79 | 4.58 | 5.94 |
| Temperature = 1 (sampling) | |||||||||||||||
| EAGLE-3 | 64 | 2.35 | 4.17 | 2.23 | 4.00 | 2.11 | 3.73 | 2.35 | 4.13 | 2.13 | 3.70 | 1.99 | 3.49 | 1.96 | 3.63 |
| DDTree | 64 | 5.28 | 5.77 | 5.68 | 6.26 | 4.94 | 5.46 | 4.65 | 5.09 | 4.65 | 5.11 | 5.28 | 5.82 | 3.50 | 4.22 |
| DDTree | 128 | 6.11 | 6.72 | 6.79 | 7.60 | 5.40 | 5.98 | 5.29 | 5.76 | 5.22 | 5.75 | 5.99 | 6.71 | 3.66 | 4.59 |
| DDTree | 256 | 6.41 | 7.17 | 7.10 | 8.13 | 5.26 | 6.20 | 5.43 | 6.03 | 5.49 | 6.12 | 6.26 | 7.17 | 3.81 | 4.88 |
| JetSpec | 64 | 5.63 | 6.19 | 5.97 | 6.60 | 4.95 | 5.48 | 5.02 | 5.52 | 5.00 | 5.51 | 5.76 | 6.38 | 3.63 | 4.37 |
| JetSpec | 128 | 6.76 | 7.49 | 7.39 | 8.36 | 5.76 | 6.49 | 5.82 | 6.39 | 5.78 | 6.39 | 6.84 | 7.74 | 3.99 | 5.01 |
| JetSpec | 256 | 7.16 | 8.03 | 7.83 | 9.01 | 5.94 | 7.06 | 6.19 | 6.85 | 6.11 | 6.83 | 7.25 | 8.29 | 4.06 | 5.22 |
Co-optimizing drafting cost and quality through causality
A speculative decoder’s speedup is the product of two terms: how many drafted tokens the target accepts, and how cheaply those tokens were drafted. Most prior work improves one term at the expense of the other. Autoregressive draft heads such as Medusa and EAGLE-3 follow the target’s own factorization and accept well, but they draft one token at a time, so throughput stays bounded by sequential drafting. Parallel block-diffusion heads draft a whole block in a single pass and pay almost nothing per token, but their positions are scored independently, so deeper tree branches drift out of agreement with the target. Retrieval drafters skip a learned model entirely, at the cost of leaning on lexical overlap or repeated text. JetSpec keeps both terms at once: it drafts an entire tree in one parallel pass, at the cost of a diffusion head, while conditioning every position on its branch prefix, at the acceptance of a causal head. That is why a larger draft budget keeps turning into a longer accepted prefix instead of saturating.
Cost and limitations
The speedups above are end-to-end and lossless, but not uniform. Sampling (T=1) margins are smaller than greedy decoding, and on the hardest reasoning sets such as AIME25 the lead over the strongest diffusion baseline narrows. Wall-clock serving speedups also run below the paper’s algorithmic speedups, because real serving adds kernel-launch and host overhead that the accepted-length ratio does not capture. The optimal draft budget is itself a trade-off: a larger tree raises accepted length but also the per-round verification cost, so the best operating point depends on the model and the hardware.
BibTeX
@misc{hu2026jetspec,
title = {JetSpec: Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting},
author = {Hu, Lanxiang and Feng, Zhaoxiang and Wu, Yulun and Yuan, Haoran and Zhao, Yujie and
Qian, Yu-Yang and Wang, Bojun and Zhao, Peng and Jiang, Daxin and Zhu, Yibo and Rosing, Tajana and Zhang, Hao},
year = {2026},
eprint = {2606.18394},
archivePrefix = {arXiv},
primaryClass = {cs.CL},
url = {https://arxiv.org/abs/2606.18394}
}Preview build: the live replay is paced from measured B200 throughput (GSM8K); the results tables are the paper’s measured numbers. §3 tree is illustrative.